 Measuring representational uncertainty
Measuring representational uncertainty
Quantifying uncertainty in protein representations across models and tasks
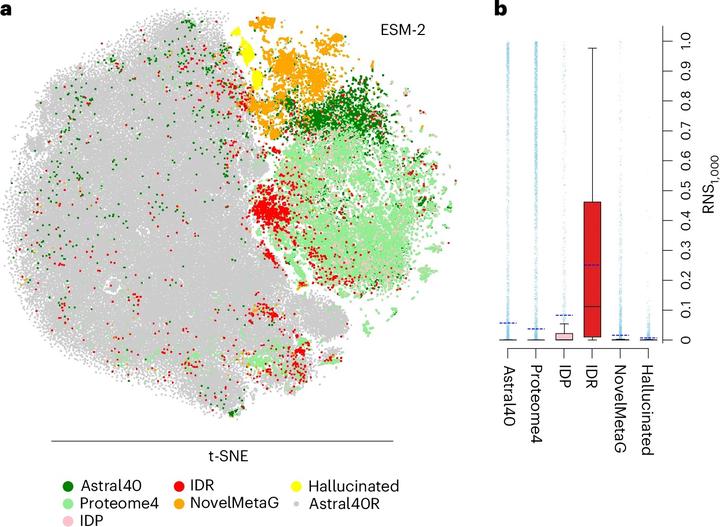
Biomolecular embeddings serve as efficient representations of sequence and structure, enabling tasks such as similarity searches, structure and function prediction and estimation of biophysical properties. However, relying on embeddings without assessing their ability to accurately represent biomolecules is a critical flaw—akin to using a scalpel in surgery without verifying its sharpness. Here we propose a means to evaluate the capacity of protein language models to encode biologically meaningful information. For each protein, representation uncertainty is scored as the fraction of non-biological ‘synthetic’ sequences among its nearest neighbors in latent space. Our analysis reveals that low-quality embeddings often fail to capture meaningful biology, displaying vector properties indistinguishable from those of randomly generated sequences. Our model-agnostic scoring framework is, to our knowledge, the first to quantify protein sequence embedding reliability. It enables embedding screening prior to downstream applications and inferences, significantly improving their reliability. We propose that embedding evaluation should be undertaken for other uses of language models in science as well.
Yana Bromberg
Principal Investigator - Professor of Bioinformatics
My research focuses on deciphering the DNA blueprints of life’s molecular machinery