 The clubber pipeline
The clubber pipeline
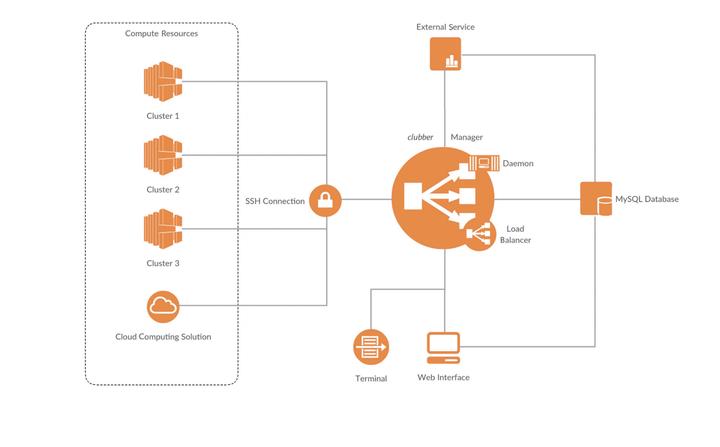
With the advent of modern day high-throughput technologies, the bottleneck in biological discovery has shifted from the cost of doing experiments to that of analyzing results. clubber is our automated cluster-load balancing system developed for optimizing these “big data” analyses. Its plug-and-play framework encourages re-use of existing solutions for bioinformatics problems. clubber’s goals are to reduce computation times and to facilitate use of cluster computing. The first goal is achieved by automating the balance of parallel submissions across available high performance computing (HPC) resources. Notably, the latter can be added on demand, including cloud-based resources, and/or featuring heterogeneous environments. The second goal of making HPCs user-friendly is facilitated by an interactive web interface and a RESTful API, allowing for job monitoring and result retrieval.
clubber is used as backend for most of our web-services, e.g. our thus super-fast pipeline for annotating molecular functionality of metagenomes (mi-faser).
Maximilian Miller
PostDoctoral Associate
improving variant effect predictions, deciphering metagenomes and creating an efficient service infrastructure